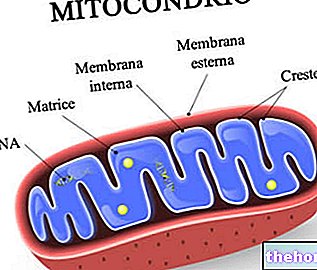
Damit die Information des Polynukleotids und die des Polypeptids übereinstimmen, gibt es einen Code: den genetischen Code.
Die allgemeinen Merkmale des genetischen Codes lassen sich wie folgt auflisten:
Der genetische Code besteht aus Drillingen und enthält keine interne Interpunktion (Crick & Brenner).
Es „wurde durch die Verwendung von „offenen Zellübersetzungssystemen“ entschlüsselt (Nirenberg & Matthaei, 1961; Nirenberg & Leder, 1964; Korana, 1964).
Es ist stark entartet (Synonyme).
Die Organisation der Codetabelle ist nicht zufällig.
Drillinge "Unsinn".
Der genetische Code ist „Standard“, aber nicht „universal“.
Wenn man sich die Tabelle des genetischen Codes ansieht, muss daran erinnert werden, dass er sich auf die Translation von "RNAm zu Polypeptid bezieht, für die die beteiligten Nukleotidbasen A, U, G, C sind. Die Biosynthese einer Polypeptidkette ist die Translation von die Nukleotidsequenz in der Aminosäuresequenz.

Jedes Basentriplett des RNAm, Codon genannt, hat die erste Base in der linken Spalte, die zweite in der oberen Reihe, die dritte in der rechten Spalte Nehmen wir zum Beispiel Tryptophan (dh Try) und wir sehen, dass das entsprechende Codon sein, um UGG. Tatsächlich umfasst die erste Basis, U, die gesamte Reihe von Kästchen oben; dabei bezeichnet G das Kästchen ganz rechts und die vierte Zeile des Kästchens selbst, in dem wir Try stehen. Um das Tetrapeptid Leucin-Alanin-Arginin-Serína (Symbole Leu-Ala-Arg-Ser) zu synthetisieren, finden wir die Codons UUA-AUC-AGA-UCA im Code.

An dieser Stelle sollte jedoch beachtet werden, dass alle Aminosäuren unseres Tetrapeptids (im Gegensatz zu Tryptophan) von mehr als einem Codon kodiert werden. Es ist kein Zufall, dass wir im gerade beschriebenen Beispiel die angegebenen Codons gewählt haben, wir hätten dasselbe Tripeptid mit einer anderen RNAm-Sequenz kodieren können, wie beispielsweise CUC-GCC-CGG-UCC.
Ursprünglich wurde der Tatsache, dass eine einzelne Aminosäure mehr als einem Triplett entsprach, eine zufällige Bedeutung gegeben, die sich auch in der Wahl des Begriffs der Degeneration des Codes ausdrückte, der verwendet wurde, um das Phänomen der Synonymie zu definieren. Andererseits deuten einige Daten darauf hin, dass die Verfügbarkeit von Synonymen, die sich auf eine unterschiedliche Stabilität der genetischen Information beziehen, keineswegs zufällig ist, was auch durch die Feststellung eines anderen Wertes des A + T / G + C-Verhältnisses bestätigt zu werden scheint in den verschiedenen Evolutionsstufen. Bei Prokaryoten beispielsweise, bei denen das Bedürfnis nach Variabilität nicht durch die Regeln des Mendelismus und Neo-Mendelismus befriedigt wird, steigt das A + T / G + C-Verhältnis tendenziell an.Die daraus resultierende geringere Stabilität gegenüber Mutationen sorgt für eine größere Chancen für Variabilität zufällig durch Genmutation.
Bei Eukaryoten, insbesondere in vielzelligen Zellen, in denen es notwendig ist, dass die Zellen des einzelnen Organismus alle das gleiche erbliche Erbe behalten, nimmt das A + T / G + C-Verhältnis in der DNA tendenziell ab, was die Möglichkeit für somatische Genmutationen verringert .
Die Existenz synonymer Codons im genetischen Code wirft das bereits erwähnte Problem der Multiplizität von Anticodons in der RNAt auf.
Es ist sicher, dass es für jede Aminosäure mindestens eine RNAt gibt, aber es ist nicht ebenso sicher, ob eine einzelne RNAt an ein einzelnes Codon binden kann oder Synonyme gleichgültig erkennen kann (insbesondere wenn diese sich nur für die dritte Base unterscheiden).
Wir können daraus schließen, dass es im Durchschnitt drei synonyme Codons für jede Aminosäure gibt, während Anticodons mindestens eins und nicht mehr als drei sind.
Wenn man sich daran erinnert, dass Gene als einzelne Abschnitte sehr langer Polynukleotidsequenzen der DNA gedacht sind, ist klar, dass der Anfang und das Ende des einzelnen Gens notwendigerweise im Gedächtnis enthalten sein müssen.
BIOSYNTHESE VON PROTEINEN
In verschiedenen Teilen der DNA findet die Öffnung der Doppelkette und die Synthese der verschiedenen RNA-Typen statt.
Während des Ladeschritts bindet die RNAt an die Aminosäuren (die zuvor durch das ATP und das spezifische Enzym aktiviert wurden). Die biosynthetische „Maschinerie“ ist nicht in der Lage, falsch geladene tRNAs zu „korrigieren“.
Das RNAr spaltet sich dann in die beiden Untereinheiten auf und führt durch Bindung an die ribosomalen Proteine zum Zusammenbau der Ribosomen.
Die RNAm, die das Zytoplasma passiert, bindet an die Ribosomen und bildet das Polysom.Jedes Ribosom, das auf dem Boten fließt, beherbergt nach und nach die RNAt, die zu den relativen Codons komplementär ist, nimmt die Aminosäuren auf und bindet sie an die Polypeptidkette in Bildung.
Die relativ stabilen RNAt gelangen wieder in den Kreislauf. Die Ribosomen werden auch wieder verwendet, wodurch das bereits zusammengesetzte Polypeptid freigesetzt wird.
Der Botenstoff, der weniger stabil ist, weil er vollständig eingliedrig ist, wird (durch die Ribonuklease) in die einzelnen Ribonukleotide gespalten.
Der Zyklus setzt sich somit fort und synthetisiert nacheinander die Polypeptide an den Boten-RNAs, die durch die Transkription geliefert werden.